切换主题
前端工程化
Webpack
module/chunk/bundle
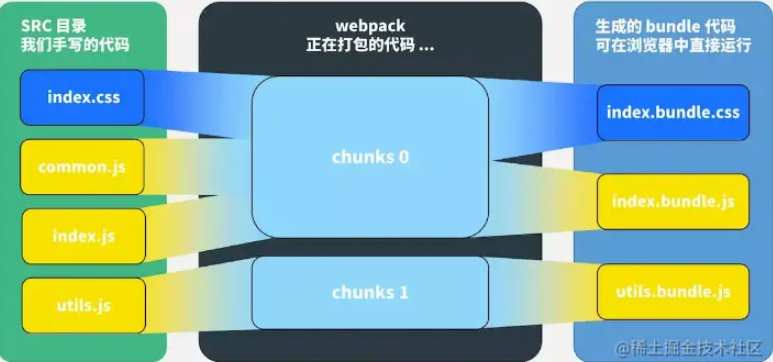
| 定义 | 介绍 | 关系 |
|---|---|---|
| module | 它可以是JavaScript文件、CSS文件、图片等,Webpack通过loader将它们转换为有效的module,以供应用程序使用。 在Webpack中,每个Module都会被转换成一个或多个Chunk,并可能包含有对其他Module的依赖。 | module是Webpack打包过程的起点和基本单位 |
| chunk | chunk是Webpack在构建过程中生成的中间产物,它代表着一组被合并在一起的modules。这些modules通常基于某种逻辑(如依赖关系、按需加载等)被组织在一起。 默认不进行任何其他配置情况下,Webpack会将所有入口点(entry point)及其依赖的模块打包到一个主要的初始chunk中。可使用代码分割拆分成多个chunk | 多个module可以组成一个Chunk,而一个chunk也可以包含多个module。 |
| bundle | bundle是Webpack最终输出的文件,它包含了所有的chunk和module。,如打包后的JavaScript文件、CSS文件、图片等。 这些文件是静态资源,可以直接被浏览器加载和解析。 | 一般来说一个 chunk 对应一个 bundle,但也有例外。比如通过MiniCssExtractPlugin 从chunk中抽离出了bundle.css文件 |
loader & plugin
| 定义 | 功能 | 执行方式 |
|---|---|---|
| loader | 本质上是一个函数,主要完成文件转换的工作。用于将文件(如.vue、.scss等)编译成Webpack能够理解和处理的模块。 | 主要在模块加载阶段执行,处理模块源代码的转换。 Loader以链式调用的方式工作,从后往前执行,每个Loader的输出作为下一个Loader的输入。 |
| plugin | Plugin主要负责执行更广泛的任务,如打包优化、资源管理和环境变量注入等,它们不直接操作文件内容。 | 在整个Webpack生命周期内,通过监听特定的事件来执行逻辑。 |
hash/chunkHash/contentHash
| 定义 | 使用范围 | 特点 | 适用场景 |
|---|---|---|---|
| hash | 整个构建过程。 | 任何一个文件改变,所有文件的hash值都会改变。 | 不推荐在生产环境中使用,会导致缓存失效的粒度过大,影响网站性能。 |
| chunkHash | 每个独立的入口chunk文件及其依赖。 | 入口文件或其依赖改变时,对应的文件名改变。 | 生产环境中管理代码分割后的文件缓存。 |
| contentHahs | 文件内容级别。 | 文件内容改变时,文件名改变。 | 管理CSS、图片等文件的缓存。 |
核心工作原理
Webpack 最核心的功能,是将各种类型的资源,包括图片、css、js等,转译、组合、拼接、生成 JS 格式的 bundle 文件。
初始化阶段
- 初始化参数:从配置文件、 配置对象、Shell 参数中读取,与默认配置结合得出最终的参数。
- 创建编译器对象:用上一步得到的参数创建 Compiler 对象。
- 初始化编译环境:包括注入内置插件、注册各种模块工厂、初始化 RuleSet 集合、加载配置的插件等。
- 开始编译:执行 compiler 对象的 run 方法
- 确定入口:根据配置中的 entry 找出所有的入口文件,调用 compilition.addEntry 将入口文件转换为用于记录模块间依赖关系的 dependence 对象。
构建阶段
- 编译模块(make):根据 entry 对应的 dependence 创建 module 对象,调用 loader 将模块转译为标准 JS 内容,调用 JS 解释器将内容转换为 AST 对象,从中找出该模块依赖的模块,再 递归 本步骤直到所有入口依赖的文件都经过了本步骤的处理。
- 完成模块编译:上一步递归处理所有能触达到的模块后,得到了每个模块被翻译后的内容以及它们之间的 依赖关系图。
生成阶段
- 输出资源(seal):根据入口和模块之间的依赖关系,组装成一个个包含多个模块的 Chunk,再把每个 Chunk 转换成一个单独的文件加入到输出列表,这步是可以修改输出内容的最后机会。
- 写入文件系统(emitAssets):在确定好输出内容后,根据配置确定输出的路径和文件名,把文件内容写入到文件系统。
HMR热更新执行原理
- 使用 webpack-dev-server (后面简称 WDS)托管静态资源,在内存中创建虚拟文件系统,同时以 Runtime 方式注入 HMR 客户端代码。
- 浏览器加载页面后,与 WDS 建立 WebSocket 连接。
- Webpack 监听到文件变化后,增量构建发生变更的模块,并通过 WebSocket 发送 hash 事件。
- 浏览器接收到 hash 事件后,请求 manifest 资源文件,确认增量变更范围。
- 浏览器加载发生变更的增量模块。
- Webpack 运行时触发变更模块的 module.hot.accept 回调,执行代码变更逻辑。
Tree Shaking原理
- Make 阶段,收集模块导出变量并记录到模块依赖关系图 ModuleGraph 变量中。
- Seal 阶段,遍历 ModuleGraph 标记模块导出变量有没有被使用。
- 生成产物时,若变量没有被其它模块使用则使用Terser删除对应的导出语句。
注意
标记功能需要配置 optimization.usedExports = true 开启
模块联邦(Module Federation)
Webpack模块联邦(Webpack Module Federation)是 Webpack 5 中引入的一项新功能,它允许不同的 Webpack构建 之间共享代码并动态加载依赖项。
核心概念:
Container
一个使用 ModuleFederationPlugin 构建的应用就是一个 Container,它可以加载其他的 Container,也可以被其他的 Container 加载。
Host & Remote
从消费者和生产者的角度看 Container,Container 可以分为 Host 和 Remote。
Host: 作为消费者,他可以动态加载并运行其他 Remote 的代码。
Remote: 作为提供方,他可以暴露出一些属性、方法或组件供 Host 使用。
注意:Container 既可以作为 Host 也可以作为 Remote。
Shared
shared 表示共享依赖,一个应用可以将自己的依赖共享出去,比如 react、react-dom、mobx等,其他的应用可以直接使用共享作用域中的依赖从而减少应用的体积。
优点
- 支持项目中直接导出某模块并单独打包。
- 相比过去, externals 无法多版本共存,dll 无法共享模块,模块联邦都可以解决。
- 支持运行时动态加载。
缺点
- 不适用于封闭性,安全性高的项目。
- 拆分粒度需要权衡,因为被共享的模块不可做tree-shaking。
- 运行时共享带来的版本控制和typing问题。
更多详情相关链接:https://juejin.cn/post/7210746685802512443?searchId=2025012520192704EA94AA49A2D3A093AC
性能优化
常见的优化方法总结:
提升编译速率
- 使用thread-loader开启多进程打包。
- 使用babel缓存,持久化缓存(filesystem)等方法缓存编译结果。
- 使用DllPlugin预编译依赖模块。将不经常变动的第三方库单独打包,避免在每次构建时都重新编译这些模块。
- 开发环境下减少监听文件,提升HMR速度。
持久化缓存
将首次构建结果持久化到本地文件系统,在下次执行构建时跳过一系列解析、链接、编译等非常消耗性能的操作,直接复用 module、chunk 的构建结果。
减小打包体积
- 压缩js,css,图片等资源。
- Tree Shaking。
- 使用CDN链接代替本地安装第三方依赖。
优化运行时体验
- 使用异步加载,例如点击某个按钮的时候才需要加载某个图片资源。
- 使用splitChunks实现代码分割(将分割成不同的 bundle,按需加载资源)。
js
module.exports = {
// ...
optimization: {
splitChunks: {
chunks: 'all', // 可以是 'all'(推荐用于生产环境)、'async(默认)' 或 'initial'
minSize: 20000, //生成 chunk 的最小体积(以字节为单位)
maxSize: 0, // 生成chunk的最大体积(以字节为单位),如果设置为 0,则没有限制
minChunks: 1, // 被至少多少个 chunk 共享时,才会被分割
maxInitialRequests: 30, // 入口点处的并行请求的最大数量
automaticNameDelimiter: '~', // 生成名称时使用的分隔符
enforceSizeThreshold: 50000, // 强制分割前需要达到的体积阈值
cacheGroups: {
// 缓存组可以继承和覆盖 splitChunks 里的选项
//创建了一个名为 vendors 的缓存组,用于将来自 node_modules 的模块分割到一个单独的 bundle 中。
vendors: {
test: /[\\/]node_modules[\\/]/,
priority: -10, // 优先级
reuseExistingChunk: true, // 如果可复用已有 chunk,则不再创建新的 chunk
},
default: false, // 禁用默认的缓存组
},
},
},
// ...
};- 预获取和预加载
预获取(prefetch):浏览器空闲的时候进行资源的拉取。
js
import(/* webpackPrefetch: true */ './test.png').then();预加载(preload):提前加载后面会用到的关键资源(慎用)。
js
import(/* webpackPreload: true */ './test.png').then();零碎
babel-loader只是将ts转成js,不包括类型检查功能。ts-loader默认转译+类型检查都支持,但不支持多线程,效率慢。fork-ts-checker-webpack-plugin采用单独线程进行类型检查,效率快,但不支持vue3。babel只负责转换新特性,而babel-polyfill负责转换新的api。
Webpack/Vite/Rspack
| 方面 | Webpack | Vite | Rspack |
|---|---|---|---|
| 开发环境 | 全量/增量打包,依赖 bundle: 需要通过构建整个项目的依赖图,进行压缩、合并、转换(非js文件需要loader转换)、分割等操作,将所有资源打包成一个或多个 bundle 文件,每次修改都需要打包。但是单线程,无法进行高度并行化计算 | 原生 ESM(浏览器直接运行 ES Modules) + 按需编译: 先启动开发服务器,利用原生 ES Module提供源码(jsx,vue等文件),无需打包(即冷启动),使用esbuild(用go编写,多线程速度快)主要针对模块化模式不统一(如CommonJs)的第三方依赖进行预构建,在浏览器需要加载某个模块时,拦截浏览器发出的请求,根据请求进行按需编译,然后返回给浏览器。 | 类似 Webpack,基于 Rust 高性能构建并采用增量打包,采用多线程并行执行,充分利用多核 CPU,提升构建速度。 |
| 热更新 | 需要把改动模块及相关依赖全部编译 。 | HMR时只需让浏览器重新请求该模块,同时利用浏览器的缓存(源码模块协商缓存,依赖模块强缓存)来优化请求。 | 类似 Webpack,但 Rust 优化,比webpack速度快 |
| 生产构建 | webpack在生产环境下会将所有代码打包成一个或多个bundle,以便进行优化、压缩和代码拆分等操作,以提高性能和加载速度。但是js只能单线程运行,无法利用多核CPU的优势,项目越大会很影响打包速度。 | 同样基于原生es module,使用rollup(esm支持良好,打包体积小,生态完善稳定)进行生产环境打包。 | 类似 Webpack,但是Rust 高性能打包,采用多线程并行执行,充分利用多核 CPU,提升构建速度。 |
| 使用成本 | webpack 概念和配置项比较复杂繁多。 | 大多常用功能(如css 预处理,分包,压缩,HMR等)已内置。 | 类似webpack的使用方式 |
| 兼容性 | 兼容性较好,能普遍兼容现有浏览器。 | 适合现代支持ES Module特性的浏览器 | 适合现代支持ES Module特性的浏览器。并且支持部分 Webpack 插件,易于从webpack迁移 |
vite生产环境为何仍需打包?打包工具又为何使用rollup而不是esbuild?
A1:生产环境的核心要求是性能优化和稳定性,这包括代码压缩分割,资源拆分,平台兼容性处理等。然而开发环境的核心要求是快速反馈即可。若直接使用原生ES Module资源部署生产环境,则无法保证代码性能和稳定性。
A2:虽然esbuild很快,但是其功能和生态尚未非常完善,特别是代码分割和 CSS 处理方面。而rollup在这些方面更加成熟和灵活。
Npm/Pnpm/Npx
| 包管理工具 | 主要特点 |
|---|---|
| npm | 所有依赖扁平化处理,安装统一提升到node_modules根目录下。会存在幽灵依赖问题。 |
| pnpm | 使用硬链接来共享依赖,在多个项目中共用同一个版本的依赖,减少了磁盘空间浪费。并且强制每个包只能访问其直接依赖,避免了幽灵依赖问题。 |
| npx | 执行安装时会在当前目录下的./node_modules/.bin里去查找是否有可执行的命令,没有找到的话再从全局里查找是否有安装对应的模块,全局也没有的话就会调用npm自动下载对应的模块(下载到一个临时目录,用完即删)。 |
硬链接 vs 软链接
硬链接:某个文件的别名。与原文件共享硬盘上的同一块数据,修改硬链接或原文件都会更新实际数据。删除原文件,硬链接依然能访问数据。软链接:存储某个文件的引用地址,相当于“快捷方式”。删除原文件后,软链接则失效。
幽灵依赖
npm安装项目依赖时,所有依赖的第三方包都会被提升到node_modules根目录,所以即时某个包没有在项目的package.json中显式声明,依然可以被引用。
这样就会存在隐患。因为如果这个包未来不再被项目中某个依赖使用,就不会被安装和提升,那么项目中引用该包就会失败报错。
Monorepo & 微前端
| 特性 | 微前端(Micro Frontends) | Monorepo |
|---|---|---|
| 核心思想 | 将一个庞大应用拆分为多个独立小应用,每个小应用可独立开发/运行/部署,小应用联合为一个完整应用 | 将多个项目放在同一个仓库中 |
| 技术栈 | 每个模块可以使用不同的技术栈 | 所有项目通常使用相同的技术栈 |
| 部署方式 | 每个模块可以独立部署 | 所有项目通常一起部署 |
| 代码共享 | 通过接口或通信机制共享数据 | 直接在仓库内共享代码 |
| 适用场景 | 大型应用,多个团队协作 | 多个相关项目,需要统一管理 |
| 工具支持 | 需要微前端框架,如Iframe(最原始的微前端方案), Single SPA ,Qiankun | 需要 Monorepo 工具,如 Nx、Lerna,Turborepo |
| 通俗比喻 | 用乐高积木搭建城市,每个团队负责一个模块 | 一个工厂,所有车间共享设备和资源 |
| 优点 | -独立开发部署 -易于维护(故障隔离) -技术栈自由 | -代码复用,例如公共的项目配置或组件 -依赖提升,相同版本依赖提升到顶层,只安装一次,节省空间 -提升多人协作效率(多项目代码/文档共享,可以了解整体项目趋势,减少沟通成本) -代码版本集中管理,项目问题快速定位 -项目配置一致,代码风格标准一致 |
| 缺点 | -复杂性提升 -需要解决模块之间通信,状态共享,样式隔离等问题 | -仓库体积过大 -不易于项目粒度的权限管理 -需要解决不同项目依赖不同版本依赖的问题 -使用npm时会存在 幽灵依赖问题(可通过pnpm解决该问题) |
Monorepo基本搭建: https://juejin.cn/post/7404777192704868362
TurboRepo
Turborepo 是一个高性能的构建系统,用于管理和优化大型 Monorepo 项目的构建和开发流程,相比传统标准Monorepo架构,其优势在于:
多任务并行执行
Turborepo 使用一种智能调度算法来决定任务的执行顺序。它会
并行执行那些彼此之间没有依赖关系的任务,而将有依赖关系的任务按正确的顺序排队执行。这种方法最大化地利用了系统的 CPU 和内存资源,同时确保了构建过程的正确性。在传统的 Monorepo 任务管理中虽然可以执行一些基本的并行操作,但通常缺乏一个综合策略来最大化并行效率,可能导致资源未充分利用。在没有智能管理的情况下,同时运行多个重资源任务可能会导致性能瓶颈,影响任务执行效率。
增量构建
增量构建意味着在构建过程中,只有自上次成功构建以来发生变化的部分才会被重新构建,而未更改的部分则会跳过,直接使用上次构建的结果。
Turborepo 首先分析项目的依赖图,包括识别各个包之间的依赖关系。这是增量构建的基础,
确保只有当依赖的包发生变化时,依赖它们的包才会被重新构建。使用文件指纹(或哈希)技术来确定文件自上次构建以来是否发生了更改。
通过比较文件的当前指纹与存储在缓存中的上一次构建指纹,Turborepo 能够快速识别哪些文件需要重新构建。
turborepo快速入门:https://juejin.cn/post/7429128606750015514?searchId=202504241740345D417E71A82AA405C0AE
其他
- 搭建专属npm镜像服务器:https://cloud.tencent.com/developer/article/1722254
- package.json文件中的
peerDependencies作用:当前项目与项目中需要安装的某个包都需要依赖于另一个包A,则可在此指定包A的版本且可共享该包