切换主题
Node.js
Node介绍
Nodejs是一个基于Chrome V8的JavaScript运行环境。它使得JS可以运行在服务器端并且可以跨平台运行(Windows,mac OS以及Linux)。
此外,与其他后端语言(如php)不同,node内置了http服务器,不需要额外部署http服务器(如Apache)。
特点
非阻塞I/O
在node中,当线程遇到IO操作时,不会以阻塞方式(即传统同步IO方式,同一时刻只能做一件事)等待IO操作完成,而是将IO请求转发给操作系统,继续执行下一条命令。当完成该IO操作后,再使用事件通知线程回来处理此事件。这样就可以不断“接单”,处理很多IO请求。
事件驱动
事件驱动的核心是异步回调函数(核心即上面的非阻塞IO)和事件循环的结合。Node会生成一个事件循环来监听事件,不断地检查是否有未处理的事件(即事件轮询)。有事件触发则调用回调函数
单线程
传统的同步IO要实现高并发则需要多个线程,当在多核CPU情况下,可有效利用多核资源,但由于IO操作一般比较耗时,所以多线程这种方案往往性能不高。而node基于非阻塞IO的单线程模式,CPU核心率一直是100%,对IO操纵进行异步处理。避免了多线程的线程切换,创建,销毁的开销和复杂性。通过异步回调和事件驱动模型,可以高性能地处理高并发。
注意
同时,单线程的弱点也在于无法利用多核CPU,因为只有一个事件循环。在CPU密集型任务情况下,会导致多核的CPU资源浪费
应用场景
node擅长:
- 前端工程化应用:如webpack等构建工具。
- 后端服务应用:如express,koa,egg等node服务端框架。
- 交互实时系统:如聊天系统,博客社交系统等一类轻量级,高流量,无复杂计算的系统。
- 基于web、canvas等多人联网游戏。
node不擅长处理 CPU 密集型的业务(如数据加密,压缩等)。
单线程 or 多线程
Nodejs主线程的JavaScript运行环境是单线程的,但通过多线程的底层架构和事件循环机制实现了高效的异步IO处理。
事件循环
Node.js 的事件循环是基于 libuv 库实现的,它是一个跨平台的 C 库,用于处理非阻塞 I/O。
在 Node.js 中,事件循环允许我们执行异步操作而不会阻塞主线程。
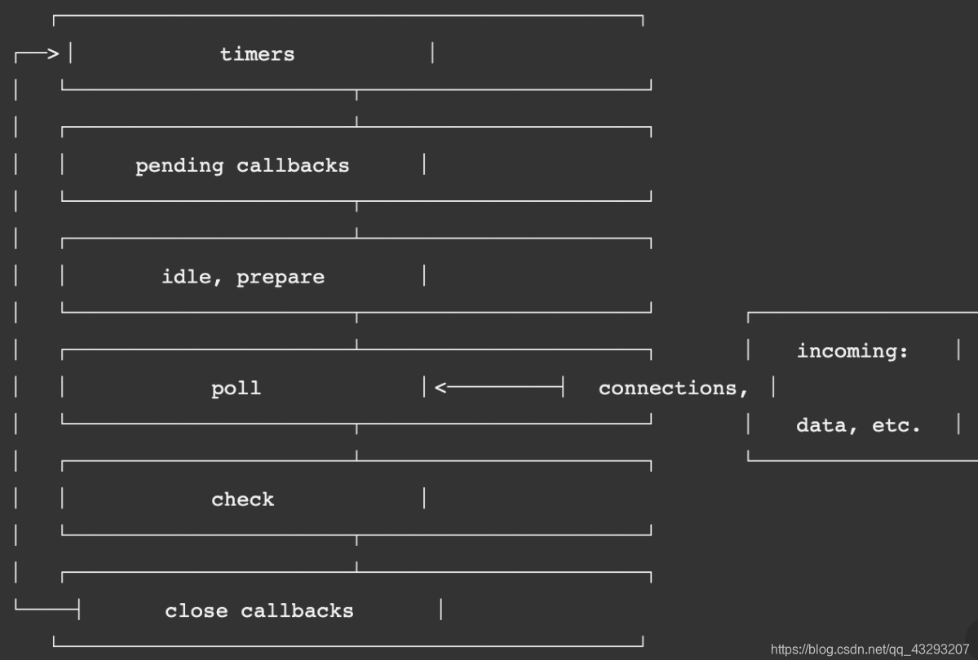
循环阶段:
- timers:执行
setInterval和setTimeout的回调函数。 - pending callbacks:执行某些系统操作(非node)的回调函数。
- idle,prepare:仅系统内部调用。
- poll:检索新的I/O事件,执行与I/O相关的回调(
包括文件IO和网络IO)。所有的事件循环以及回调处理都在这个阶段执行。其他情况nodejs将会在适当时进行阻塞。 - check:执行
setImmediate的回调函数,但不是立即执行,而是poll阶段中没有新的事件处理时再执行(即setImmediate的回调函数会在所有回调函数执行完再执)。 - close callbacks:执行一些关闭的回调函数,如 socket.on('close', ...)。
注意
setTimeout 如果不设置时间或者设置时间为 0,则会默认为 1ms。此时,主流程执行完成后,超过 1ms 时,会将 setTimeout 回调函数逻辑插入到待执行回调函数poll 队列中;
循环的发起点:
- Node.js 启动后;
- setTimeout 回调函数;
- setInterval 回调函数;
- 也可能是一次 I/O 后的回调函数。
循环任务及优先级:
事件循环主要包含微任务和宏任务:
微任务:
Promise,Process.nextTick(优先级高于Promise)宏任务:
setTimeout、setInterval、setImmediate 和 I/O(包括文件IO和网络IO)
循环终点:
当所有的微任务和宏任务都清空的时候,虽然当前没有任务可执行了,但是也并不能代表循环结束了。因为可能存在当前因为其他回调函数阻塞导致还未回调的异步I/O,所以这个循环是没有终点的,只要进程在,并且有新的任务存在,就会去执行。
node中的微任务在事件循环中优先级最高(即优先执行),宏任务在微任务执行之后执行。
在同一个事件循环周期内,如果既存在微任务队列又存在宏任务队列,那么优先将微任务队列清空(全部执行完毕),再执行宏任务队列。在主线程处理回调函数的同时,同理也需要判断是否插入微任务和宏任务。
注意
当同时碰到setTimeout和I/O的宏任务,只有当setTimout设置时间为0时,其回调才会必定优先比I/O回调优先执行,除此之外,二者的回调执行顺序不可保证。
示例1:
js
import fs from 'fs';
// 扔进宏任务队列
setTimeout(() => {
// 第4次打印(与setImmediate回调说不好哪个优先,这里假设setImmediate优先级高)
console.log('setTimeout callback');
fs.readFile('./test1.txt', {encoding: 'utf-8'}, (err, data) => {
if (err) throw err;
// 第6次打印(不一定,看读取速率或文件大小)
console.log('read file test1.txt success');
});
}, 0);
// 扔进宏任务队列
fs.readFile('./test.txt', {encoding: 'utf-8'}, (err, data) => {
if (err) throw err;
// 第5次打印(不一定,看读取速率或文件大小)
console.log('read file test.text success');
});
/// 扔进宏任务队列
setImmediate(()=>{
// 第3次打印(与setTimeout(0)的回调说不好哪个优先,这里假设其优先级高)
console.log('setImmediate callback');
})
/// 扔进微任务队列
Promise.resolve().then(()=>{
// 唯一的微任务,微任务优先级高,第2次打印
console.log('Promise then');
});
//主线程同步代码完成后开始第一次事件循环,第1次打印
console.log('main finished');示例2:
js
import fs from 'fs';
// 扔进宏任务队列
setTimeout(() => {
//假设比test.txt文件读取快,第2次打印
console.log('setTimeout callback');
sleep(10000)
//主线程阻塞了10s后,第3次打印
console.log('sleep finished');
}, 0);
// 扔进宏任务队列
fs.readFile('./test.txt', {encoding: 'utf-8'}, (err, data) => {
if (err) throw err;
//假设文件读取比sleep执行完毕所用时间短,但由于sleep过程中主线程阻塞了10s,所以不会立即执行readFile回调
// 等待sleep执行完毕,主线程执行结束后立即执行此回调,第4次打印
console.log('read file success');
});
function sleep (n) {
const start = new Date().getTime() ;
while (true) {
if (new Date().getTime() - start > n ) {
break;
}
}
}
//主线程同步代码完成后开始第一次事件循环,第1次打印
console.log('main finished');Nodejs作为中间服务器的理解
后端出于性能和别的原因,提供的接口所返回的数据格式也许不太适合前端直接使用(比如一些核心的公共接口,不可能满足所有场景需求的数据格式),前端所需的排序功能、筛选功能,以及到了视图层的页面展现,也许都需要对接口所提供的数据进行二次处理。这些处理虽可以放在前端来进行,但也许数据量一大便会浪费浏览器性能。
后端接口拆的比较细的情况下,前端需要一次请求多个接口(前端需写多个请求的代码且浏览器有并行请求数量控制。页面数据渲染常常需要等待资源到齐才能进行,会出现短暂白屏与闪动。尤其在移动设备低速网路的情况下体验奇差无比)。而采用node做服务去请求多个接口并根据页面需求处理数据格式转换进行整理多个接口返参为统一数据进而转发给前端。
这样与传统的前后端分离模式比较更加完善,可以让前端专注于视图层,而数据处理逻辑交由node中间服务。
读取文件
js
const fs = require('fs');
// 创建一个可读流
const readStream = fs.createReadStream('large-file.txt');
// 监听 'data' 事件以接收数据块
readStream.on('data', (chunk) => {
console.log(`Received ${chunk.length} bytes of data.`);
// 在这里处理数据块,例如写入另一个文件或进行其他操作
});
// 监听 'end' 事件以知道何时读取完成
readStream.on('end', () => {
console.log('File has been read in full.');
});
// 监听 'error' 事件以处理读取过程中可能发生的错误
readStream.on('error', (err) => {
console.error(`Error occurred: ${err.message}`);
});js
const fs = require('fs');
fs.readFile('large-file.txt', 'utf8', (err, data) => {
if (err) {
console.error(`Error occurred: ${err.message}`);
return;
}
console.log(`Received ${data.length} bytes of data.`);
// 在这里处理整个文件的内容,但由于是一次性加载到内存,可能会占用大量内存
});两种文件读取方式的区别:
内存使用
使用流时,你只需在内存中
保留一个较小的数据块。当读取大型文件时,这是非常有用的,因为它允许你以较小的内存占用处理文件。而 fs.readFile 会将
整个文件内容加载到内存中,这可能会消耗大量内存,并可能导致性能问题或内存溢出。数据处理
使用流时,你可以在每个数据块到达时立即处理它,而不是等待整个文件被读取。这使得你可以
实时处理数据,例如将数据写入另一个文件或进行流式传输。而 fs.readFile 则
需要等待整个文件被读取到内存中后才能开始处理。异步/同步
虽然两个示例都展示了异步的使用方式,但 fs.readFile 也可以以同步方式使用(fs.readFileSync),这会阻塞事件循环直到文件被完全读取。
然而,
流始终是异步的。
其他
- 不建议在对文件进行读写操作前使用
fs.stat来检查文件是否存在,因为在检查和读写操作中间,其他进程有可能更改文件的状态,导致检查不可靠。应该直接读写文件,如果文件不存在则会回调中引发错误,处理错误即可。